|
|
|
|||
|
|
||||
|
||||
|
|
Australasian Agribusiness Review - Vol. 13 - 2005Paper 7 Efficiency Measurement of Australian Dairy Farms: National and Regional Performance
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dairy SA |
Tasmania |
DIDCO |
Gipps |
Murray |
Sub-Tropical |
WestVic |
Western |
|
Number of farms |
130 |
179 |
191 |
295 |
308 |
265 |
280 |
94 |
Milk Output (000’s megalitres) Mean Min Max |
1,029 70 5,000 |
896 103 4,300 |
807 115 4,000 |
876 118 5,500 |
993 80 9,000 |
578 80 2,200 |
1,168 900 7,500 |
1,190 314 4,500 |
Hectares Mean Min Max |
147.1 12 1497 |
112.3 20 465 |
103.2 20 486 |
98.1 20 526 |
116.5 16 607 |
140.8 16 898 |
145.8 30 1300 |
206.5 51 800 |
Cow Numbers Mean Min Max |
182 22 730 |
219 32 250 |
156 40 750 |
200 36 1150 |
204 38 1600 |
138 30 600 |
237 30 1300 |
207 60 800 |
Feed ($per cow) Mean Min Max |
2.06 0 12.5 |
0.49 0 5.78 |
1.67 0 8.0 |
0.83 0 5.78 |
1.38 0 5.56 |
1.32 0 12.6 |
1.2 0 5.05 |
1.61 0 8.3 |
Irrigation (hecs) Mean Min Max |
43.28 2 263 |
44.3 4 243 |
41 4 162 |
70.3 4 405 |
92.3 4 668 |
28.8 4 243 |
44.1 2 280 |
43.34 12 101 |
Fertilizer(000’s $) Mean |
14 |
25 |
17 |
17 |
15 |
13 |
24 |
26 |
Capital (000’s $) Mean |
1,021 |
815 |
1,073 |
845 |
901 |
823 |
801 |
1,588 |
Table 1 shows that individual dairy regions differ in terms of quantity of milk produced as well as the production technology and mix of inputs used. Western region had the highest average megalitres of milk output, just ahead of WestVic and Dairy SA, with Sub-Tropical the lowest. Average farm size varied from 98 hectares in Gipps to 206.5 hectares in Western. Cow numbers were more consistent, with five regions having an average of more than 200. The higher irrigation regions, namely Murray and Gipps, had much lower fertilizer expenditure compared to Tasmania and WestVic. The use of supplementary feed was significant for all regions except Tasmania. The capital value of the farms varied across the regions, from a high of $1,587,766 in Western to $815,643 in Tasmania.
Our results are presented in the following order. First, we present TE estimates for the whole sample set assuming CRS. This allows us to examine the relative performance of all dairy regions. We also present TE results including and excluding irrigation to illustrate how the choice of variables used in the analysis affects the efficiency estimates derived. Second, we estimate CRS TE for each region individually. We correct these estimates for differences in sample size following Zhang and Bartels (1998) by employing bootstrapping. Third, VRS results are presented for each region so that farms operating at constant, increasing, and decreasing returns to scale can be identified and the optimal scale of production (i.e., by herd size) for each region determined.
Employing a CRS specification for the whole sample we found that sixty-three (63) or 3.6 per cent of the farms were regarded as being TE (q = 1). The distribution of mean TE estimates is illustrated in Figure 1 and summary statistics reported in Table 2.
Region |
Australia |
Dairy SA |
Tasmania |
DIDCO |
Gipps |
Murray |
Sub-Trop |
West Vic |
Western |
No.Farms |
1742 |
130 |
179 |
191 |
295 |
308 |
265 |
280 |
94 |
Mean |
0.589 |
0.622 |
0.603 |
0.573 |
0.614 |
0.578 |
0.521 |
0.614 |
0.625 |
Minimum |
0.131 |
0.17 |
0.252 |
0.228 |
0.221 |
0.131 |
0.148 |
0.215 |
0.253 |
Maximum |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
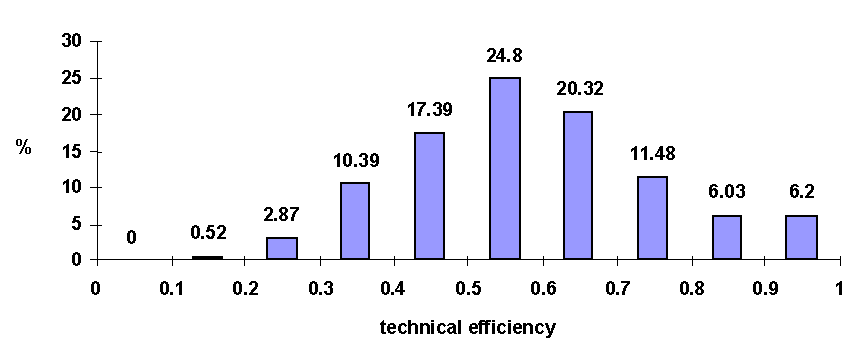
Figure 1 shows that the distribution of average TE is almost normal in shape. The average estimate of TE is 0.59. Half the farms in the sample had a TE of between 0.47 and 0.69. The least efficient farm with an estimate of 0.131 is in the Murray region. For this farm, inputs consumed could be reduced by 86.9 per cent without any reduction in output.
The average level of TE in this study is much lower than found in other studies, both in Australia and overseas, and is a reflection of the size of the sample used. Fraser and Cordina (1999) sample of 50 farms in northern Victoria had an average efficiency of 0.86 over a two-year period. This is comparable to overseas studies in New Zealand and Canada where farms had an average efficiency of 0.83 to 0.92 respectively (see Jaforullah and Whiteman, 1999, Cloutier and Rowley, 1993, and Weersink et al., 1990).
Table 2 also provides a regional breakdown of the results. The best performing regions, that is, those regions whose mean level of efficiency is above the national average are Gipps, WestVic, Tasmania, Dairy SA and Western. Western with a mean of 0.625 was the best performer. The remaining three regions, Sub-Tropical, Murray and DIDCO were the poorer performers. These results support the conjecture that Queensland and New South Wales milk marketing arrangements prior to deregulation in 2000 gave rise to less efficient dairy production relative to other regions of Australia.
Performance evaluation of dairy farms over all Australia brings in many variables that differ considerably across the nation. Climatic conditions differ widely and produce different reliance on, for example, the need to irrigate, or the need to introduce supplementary feeding. The production technologies adopted by farms reflect such regional differences. For example, Table 1 reports differences in the extent of irrigation use. In the Murray region, where approximately 80 per cent of the farms irrigate, an average of 92 hectares per farm is irrigated, while in Sub-Tropical, where only 21 per cent of the farms irrigate, an average of 29 hectares per farm is irrigated. Grouping all the regions together to examine the efficiency of Australian dairy farms, gives no recognition to such regional differences. If, for example, irrigation is included as an input in the model estimated, the efficiency results obtained will be biased in favour of those farms that do not need to rely on irrigation.
To highlight the importance of model specification we repeat the same analysis i.e., CRS for whole sample, but we only employ five inputs, leaving out irrigation. This analysis illustrates a potential weakness in DEA analysis if insufficient detail is paid to the mix of farms and farm systems included within a sample. Statistical summaries are presented in Table 3.
Region |
Australia |
Dairy SA |
Tasmania |
DIDCO |
Gipps |
Murray |
Sub-Trop |
West Vic |
Western |
No.Farms |
1742 |
130 |
179 |
191 |
295 |
308 |
265 |
280 |
94 |
Mean |
0.530 |
0.581 |
0.545 |
0.511 |
0.536 |
0.563 |
0.475 |
0.533 |
0.493 |
Minimum |
0.131 |
0.17 |
0.222 |
0.165 |
0.189 |
0.131 |
0.142 |
0.213 |
0.238 |
Maximum |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0.845 |
As shown in Table 3 the range of TE is between 0.131 to 1, but with a slightly lower mean of 0.53 compared to the six input model specification. All dairy regions have a lower level of TE, but some show much greater changes. Western, the best performer with six inputs now ranks seventh as a result of TE dropping 14 per cent from 0.63 to 0.49. Murray rises from being ranked sixth to being second behind Dairy SA. The farms in Dairy SA and Murray showed greater consistency in both analyses than did farms in any other region.
The reason for this result is obvious. The output of farms reflects inputs used, including for most farms in the Murray region, irrigation. These farms have the same output whether or not irrigation is included as an input in the model. Since most farms have a value for the irrigation input, their TE estimate does not vary much when irrigation is excluded. The farms that have lower TE efficiency are those that do not irrigate.
A simple way to compare the impact of model specification is to examine the performance of best and worst performing farms by region. Table 4 summarizes the performance of the top and bottom 50 farms in each region, with and without irrigation as an input in the model.
Dairy Region |
Irrigation Input |
No Irrigation Input |
|||
Efficient |
Bottom 50 |
Efficient |
Top 50 |
Bottom 50 |
|
Dairy SA. |
7(5.4%) |
3(2.3%) |
6(4.6%) |
6(4.6%) |
2(1.5%) |
Tasmania |
12(6.7%) |
2(1.1%) |
6(3.3) |
10(5.6%) |
3(1.7%) |
DIDCO |
6(3.4%) |
7(3.7%) |
3(1.5%) |
3(1.5%) |
9(4.7%) |
Gipps |
3(0.2%) |
1(0.3%) |
2(0.2%) |
3(1%) |
1(0.3%) |
Murray |
13(4.2%) |
8(2.6%) |
11(3.5) |
13(4.2%) |
8(2.6%) |
Sub-Tropical |
12(4.5%) |
18(6.8%) |
6(2.3%) |
8(2.8%) |
16(6.0%) |
West Vic |
9(3.2%) |
10(3.6%) |
4(1.4%) |
7(2.5%) |
9(3.2%) |
Western |
1(1.1%) |
1(1.1%) |
0 |
0 |
2(2.1%) |
All Australia |
63 (3.6%) |
50(2.8%) |
38(2.2%) |
50(2.8%) |
50(2.8%) |
The analysis shows that all regions suffered a decrease in the number of fully efficient farms when irrigation was excluded. The proportion of fully efficient farms fell from 3.6 per cent (63 farms), to 2.2 per cent (38 farms). A closer examination of the regions in terms of the fully efficient and the least efficient farms reveals the importance of selecting the correct inputs for the analysis. Tasmania and the Sub-Tropical regions both lost six efficient farms, but only one in Tasmania remained outside the top 50 farms. The Sub-Tropical region experienced significant changes, with four previously fully efficient farms remaining outside the top 50 farms, and one experiencing a fall to 0.35 and another to 0.65. The top regional performer, Western, had no fully TE farms, the top performer achieving only 0.85 efficiency.
Although these changes appear to be significant it is necessary to statistically test the results. A Spearman Rank Correlation Coefficient, (SRCC) is estimated as a statistical check on the consistency of two model specifications in terms of in the relative ranking of the farms. The SRCC statistically tests if the relative rank of farms changes when employing the different model specifications. The SRCC test statistic is calculated as follows:
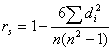 (2)
(2)
where di is the difference between the rankings for each observation (i.e., farm) under the different model specifications and n is the sample size. [3]
The hypothesis tested is:
H0: rs = 0; there is no relationship between the model specifications
H1: rs ¹ 0; there is a relationship between the model specifications
With n>30, rs is approximately normally distributed with mean zero and standard deviation 1/(n-1)0.5, so that the Z test is Z = rs(n-1)0.5. An SRCC estimate of 0.88 was obtained allowing us to reject the null hypothesis indicating that a strong positive statistically significant correlation exists between the TE estimates obtained by the two models. Thus, the ranking of farms is statistically invariant to the model specifications examined here.
In aggregate, with the data and models examined here model specification has little impact on the best and poorest performers. There is one notable exception, the Western region, whose overall performance and ranking relative to the other dairy regions changes significantly. But, statistically the results produced by either specification in terms of the rank of farms is the same.
To take account of differences in regional production technologies and variables, many of which are beyond the control of farmers, we now undertake efficiency analysis for each individual region. This means that farms will then only be compared to farms operating within the same region. Hence, the results allow us to measure how much within region TE could be increased. However, we do not consider it appropriate to directly compare differences in TE between the regions because in this analysis we are assuming that regional production technologies are different. To make a meaningful region-by-region comparison it is necessary to assume that the production technology is the same across regions and if this is the case we can consider regions in the same sample. Thus, the results presented for the whole sample provide the most consistent estimates of the relative performance of the eight dairy regions in Australia. [4]
In this section we present two sets of CRS TE results. First, we estimate TE for each region using all data assuming five and six inputs. Second, we follow Zhang and Bartels (1998) and employ a simple bootstrap procedure to take account of differences in sample size between regions. They illustrated the importance of the bootstrap procedure using Monte Carlo simulations that as the number of firms increases in a sample the estimates of TE fall. We undertake this procedure so that we produce a consistent estimate of the potential increase in TE within a region compared to all other regions.
The Zhang and Bartels (1998) bootstrap procedure is very simple.
We employ the bootstrap procedure with the five input model specification. All results are presented in Table 5.
Dairy SA |
Tasmania |
DIDCO |
Gipps |
Murray |
Sub-Trop |
WestVic |
Western |
|
No. Farms |
130 |
179 |
191 |
295 |
308 |
265 |
280 |
94 |
Average TE (6 inputs) |
0.794 |
0.722 |
0.729 |
0.705 |
0.729 |
0.638 |
0.737 |
0.822 |
Average TE (5 inputs) Bootstrap* Adjusted Average TE (5 inputs) |
0.720 0.789 (0.069) |
0.655 0.771 (0.116) |
0.662 0.817 (0.155) |
0.675 0.814 (0.139) |
0.693 0.796 (0.103) |
0.626 0.719 (0.093) |
0.680 0.725 (0.045) |
0.817 0.817 (0.000) |
* The number in the bracket is the difference between the adjusted and unadjusted average TE
The results in Table 5 reveal several interesting issues. First, the TE estimates for all regions for both five and six inputs are significantly higher compared to the TE estimates for the whole sample. This result is important. It clearly illustrates the relative nature TE estimates derived using DEA. Second, as demonstrated earlier, moving from a six to five input model specification reduces TE estimates in all regions.
Third, the bootstrap results show that for all regions, except Western which is the sample size of the bootstrap procedure, when we take account of differences in sample size TE estimates increase. That is, the adjusted bootstrap estimates are all much closer than indicated by unadjusted analysis. In terms of a region-by-region analysis Western still has the highest level of average TE but it is now equal with DIDCO. These results mean that for the prevailing dairy production technology in these regions that input use could be reduced by approximately 18 per cent. Also the Sub-Tropical region has the lowest average level of TE implying that the average farm in this region has more to gain from attaining best practice compared to all other regions.
Fourth, the bootstrap results indicate that there is a non-monotonic relationship for the regions between the increase in adjusted TE and unadjusted TE and sample size. For example, DIDCO has a sample of 191 farms, which is by no means the largest, but it does experience the biggest increase when adjusting TE. The variation in the results highlights the fact that the underlying distribution of TE differs between regions and that this impacts on the bootstrap results.
We now present results examining optimal scale of production. We estimate VRS and NIRS DEA specifications in all regions, so that IRS, CRS and DRS can be identified. We then match herd size with those farms operating at CRS within in each region so that the optimal scale of production can be determined. Table 6 presents SE results for all regions.
Dairy Region |
CRS |
IRS |
DRS |
Mean Herd size CRS farms |
Herd increase on region average |
Dairy SA |
26.2 |
69.9 |
3.9 |
224 |
42 |
Tasmania |
22.4 |
68.1 |
9.5 |
268 |
49 |
DIDCO |
15.7 |
76.4 |
7.9 |
211 |
81 |
Gipps |
15.3 |
76.6 |
8.1 |
271 |
71 |
Murray |
14.3 |
65.6 |
20.1 |
241 |
37 |
Sub-Tropical |
14.3 |
78.5 |
7.2 |
204 |
66 |
WestVic |
17.8 |
73.2 |
8.9 |
272 |
35 |
Western |
22.3 |
69.2 |
8.5 |
286 |
79 |
In keeping with previous results in the literature (e.g., Weersink et.al., 1990, Jaforullah and Whiteman, 1999, and Fraser and Cordina, 1999) few farms in any region are operating at DRS. Farms generally are not too big. The only exception is the Murray region where 20% of farms were operating at DRS.
In all regions, upward of 65 per cent of farms could improve SE if they increased scale in terms of land or herd size, for example. Using herd size as a measure of scale, the optimal scale of production for each region is determined. The fourth column in Table 6 indicates average herd size of farms within a region operating at CRS. The fifth column shows by how much average herd size needs to be increased within each region if all farms operated at CRS. These results indicate that the potential increase in herd size is high in many regions, especially DIDCO and Western.
We can see from these results that there are significant differences in the scale of operation as measured by herd size across the regions of Australia. Sub-Tropical has the smallest average herd size with 204 and Western the largest at 286. Although each region has a different optimal herd size the analysis does suggest two distinct groupings of dairy regions: 200-220 cows; and 270 plus. Only the Murray region has a herd size in-between. Thus, although the competitive pressure brought about by the deregulation of milk marketing will continue to pressure farms to grow larger, there are important regional differences in optimal target herd size. Whether these regional differences will remain, as the market for milk continues to adjust as a result of deregulation, is a question that requires further research.
This paper has employed DEA to measure TE and SE for a large sample of Australian dairy farms. Our results provide ex post support for the view that inherent inefficiency in milk production as a result of prevailing milk marketing structures would mean that dairy deregulation in 2000 would have a greater impact on dairy farming in Queensland and New South Wales than compared to Victoria. Thus, the differences we identify in TE between the regions when we assume that there exists a common production technology and prevailing institutional and environmental factors, is in keeping with our prior expectations. However, regardless of the model estimated, there are a large number of efficient farms, but there are also many, across all eight dairy regions, who are technically inefficient and whose output could be increased without changing the level of their input use.
Specifically, our results also indicated that only minor variations in TE occur when we adjust model specification. We examined how the inclusion/exclusion of irrigation affected TE estimates. Our SRCC estimates provide statistical support for the robustness of the TE estimates under either models specification. That is, the relative rank in terms of the TE estimate for a farm is invariant to the model specification.
When using the whole data set, estimates of TE are derived from comparing farms drawn from different climatic and physical conditions as well assuming a common production technology. To take account of the regional differences we re-estimated TE for each of the eight dairy regions individually. The analysis revealed several important results. First, the size of the sample impacts upon the TE estimates obtained. Reducing the sample size and examining regions individually improves the overall performance of both a region and farms with the region i.e., they have higher TE. However, within region analysis means that farms are being compared to farms that are far more likely to be facing similar climatic and geological factors. Second, only by adjusting sample size following the bootstrap procedure of Zhang and Bartels (1998) can we ascertain by how much TE within each region can potentially increase compared to other regions.
We have also found that many farms across all regions are operating at below the optimal scale of production. In terms of herd sizes, all regions could increase their scale of operation, although just how large the herds should be varies between the regions. This variation in optimal scale between herd sizes suggests that a range of farm sizes may well continue to exist across all dairy regions.
Finally, in this paper efficiency has only been examined in relation to TE and SE. No cost data has been considered or a measure of labour use. As we previously acknowledge the lack of labour use data means that the results presented here do need to be treated with some degree of caution. Furthermore, many socio-economic factors such as farmer age, level of education, and off farm employment may also account for differences in efficiency we find. Previous research has found that age and educational level impact on technical efficiency (Kumbhakar et al., 1991, and Tauer and Siefanades, 1998). We have also ignored the environmental impact of dairy farming that may become more important in terms of efficiency of operation. For example, to what degree does efficiency levels impact on sound environmental practices such as waste handling? These issues remain an area for future research.
The authors would like to thank DRDC for making the data available and Paul Kim for helping with the GAUSS code used to run the bootstrap analysis.
ABARE (Australian Bureau of Agricultural and Resource Economics) (2001), ‘Australia's Expanding Dairy Industry: Productivity and Profit’, Canberra
ABARE (Australian Bureau of Agricultural and Resource Economics) (2002), Production, Efficiency and Productivity of Australian Dairy Farms. Report to DRDC.
ACCC (Australian Competition and Consumer Commission) (2001), ‘Impact of Farmgate Deregulation on the Australian Milk Industry’, Monitoring Report, Canberra.
Ashton, D and Spencer, D. (2002), Dairy: Outlook for 2006-07, Australian Commodities, 9, 63-69.
Chambers, R.G., Fare, R., Jaenicke, E. and Lichtenberg, E. (1998), Using Dominance in Forming Bounds on DEA Models: The Case of Experimental Agricultural Data, Journal of Econometrics, 85, 189-203.
Charnes, A., Cooper, W.W. and Rhodes, E. (1978), Measuring the Efficiency of Decision Making Units, European Journal of Operational Research, 2, 429-444.
Cloutier, L. M. and Rowley, R. (1993), Relative Technical Efficiency: Data Envelopment Analysis and Quebec's Dairy Farms, Canadian Journal of Agricultural Economics, 41, 169-176.
Coelli, T.J. (1996), A Guide to DEAP Version 2.1: A Data Envelopment Analysis (Computer) Program, CEPA Working Paper 96/08, Centre for Efficiency and Productivity Analysis, University of New England.
Coelli, T.J., Rao, P.D.S. and Battese, G. (1998), An Introduction to Efficiency and Productivity Analysis, Kluwer Academic Publishers: Massachusetts.
Doucouliagos, H. and Hone, P. (2000), Deregulation and Subequilibrium in the Australian Dairy Processing Industry, The Economic Record, 76, 152-162.
Edwards, G. (2003), The Story of Deregulation in the Dairy Industry, Australian Journal of Agricultural and Resource Economics, 47, 1-24.
Farrell, M.J. (1957), The Measurement of Productive Efficiency, Journal of the Royal Statistical Society, A CXX, 253-290.
Fraser, I.M. and Cordina, D. (1999), An Application of Data Envelope Analysis to Irrigated Dairy Farms in Northern Victoria, Australia, Agricultural Systems, 59, 267-282.
Jaforullah, M. and Whiteman, J. (1999), Scale Efficiency in the New Zealand Dairy Industry: a Non-parametric Approach, The Australian Journal of Agricultural and Resource Economics, 43, 523-541.
Kumbhakar, S.C., Ghosh, S. and McGuckin, J.T. (1991), A Generalized Production Frontier Approach for Estimating Determinants in US Dairy Farms, Journal of Business and Economic Statistics, 9, 279-286.
Simar, L. and Wilson, P.W. (2000), Statistical Inference in Nonparametric Frontier Models: The State of the Art, Journal of Productivity Analysis, 13, 49-78.
Sincich, T. (1996), Business Statistics by Example, Prentice Hall: New Jersey
Tauer, L. and Siefanades, Z. (1998), Success in Maximising Profits and Reasons for Profit Deviation on Dairy Farms. Applied Economics, 30, 151-156.
Weersink, A., Turvey, C.G. and Godah, A. (1990), Decomposition Measures of Technical Efficiency for Ontario Dairy Farms, Canadian Journal of Agricultural Economics, 38, 439-456.
Zhang, Y. and Bartels, R. (1998), The Effect of Sample Size on the Mean Efficiency in DEA with an Application to Electricity Distribution in Australia, Sweden and New Zealand, Journal of Productivity Analysis, 9, 187-204.
[1] The data is analysed using DEAP Version 2.1 (Coelli, 1996) and GAUSS Version 3.2.
[2] We do not include a measure of labour as the survey did not collect this information. The exclusion of this variable will bias our results to a certain extent and needs to be borne in mind when interpreting the findings presented.
[3] The SRCC is described in detail in Sincich, (1996).
[4] As Simar and Wilson (2000) note, the statistical properties of the DEA estimator are such that larger samples are to be preferred. This implies that aggregating data from different regions to increase sample size is desirable if the production technology is the same.
|
Contact the University : Disclaimer & Copyright : Privacy : Accessibility |
|
Date Created: 03 June 2005 |
The University of Melbourne ABN: 84 002 705 224 
|